Competitor Teardowns—using Patents

Competitor teardowns are nothing new—you get hands on your competitor’s hot new product and strip it back to its components.
You can work through compromises made, corners cut, opportunities missed.
Component performance, suppliers, and costing can also be analysed. The value compounds when you track the same product line over successive release cycles, to the point you can plot your competitor’s trajectory and anticipate next moves.
All this valuable intel can inform your own product development and make for plans to re-capture the lead with your next product iteration.
Why not do that with your competitor’s patents?
Patents are public, and they’re potentially rich in revealing information. This information is not always embedded in commercially offered products.
And with the advent of AI tools in the form of easy access to LLM inference tools it’s never been easier and quicker to execute repeatable analyses of this type.
Tesla’s Smart Summon feature and patent
Let’s take the simplest of examples—looking at a single competitor patent.
Just for no particular reason I picked a pot luck patent as the most recently published patent for which Elon Musk is a named inventor.
US20230176593A1 was soon identified as a published patent application made by Tesla, Inc, and which names Elon Musk amongst many others as inventors. The application was published June 8, 2023 and is entitled ‘Autonomous and User Controlled Vehicle Summon to a Target’.

[FIG 1]
The cover sheet of this patent application is reproduced in Fig 1 above—the details here are brief, and form bibliographic details as well as some (fairly cryptic) technical details by way of a written abstract and accompanying diagram. If you have any interest, you can easily access the full details of the patent publication including the entire PDF as published by United States Patent and Trademark Office (USPTO) via its page on Google Patents.
I was going to add that patent information is often available before a product’s release—but a quick double check indicates the product (or feature in this case) was already ‘in market’ as Smart Summon.
Here pictured below is Smart Summon described in the Model Y manual, and it looks this feature was withdrawn across the range at some point, and reintroduced following revision in 2023. Crashes? Malfunctions? Who knows! It was promised to return in March 2024, and apparently did some point between then and now.
So, yes, the selected patent application probably revealed some product information a year before the commercial re-release.
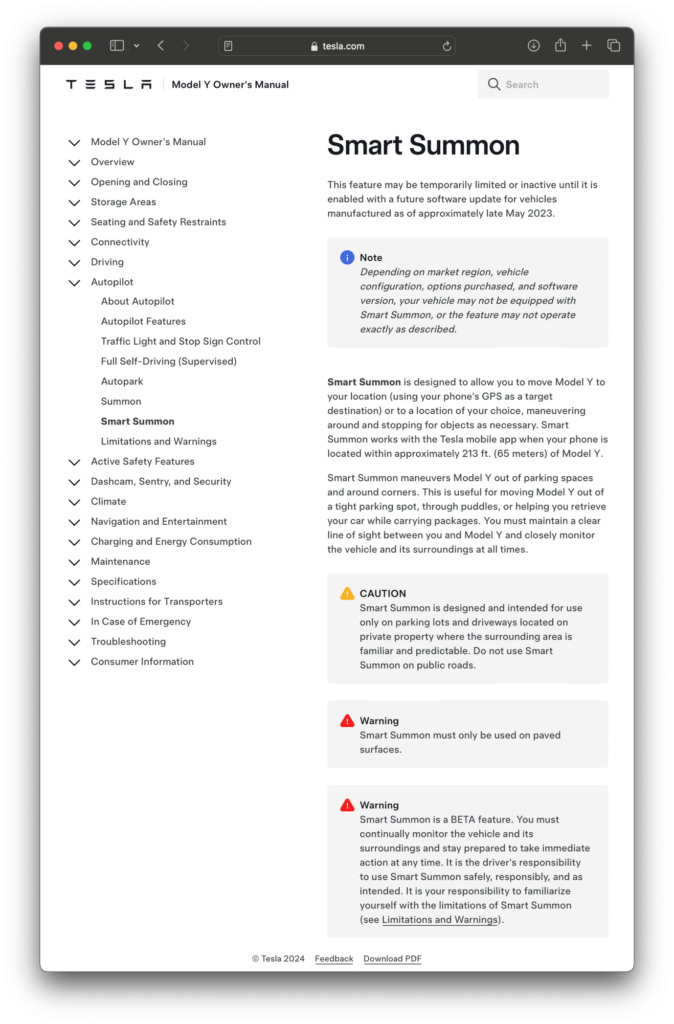
[FIG 2]
Fig 2 above is a screenshot of the head of the relevant page of the Model Y manual for Smart Summon. It hasn’t been a smooth ride for Smart Summon.
So you can imagine the selected patent publication overlaps with some further development made prior to reintroduction of this feature.
Illustrative teardown session
Actual teardown can be as simple or complicated as you wish.
Here, the following Fig 3 and Fig 4 below form the simplest of examples in the form of a highly truncated Q&A using the easily accessible ChatGPT app interrogating the example patent publication US20230176593A1 submitted in PDF form.

[FIG 3]
![]()
[FIG 4]
My first discussion with this patent was longer and more free-wheeling and I was honestly blown by the reply when I asked for a list of possible disruptive S-curve jumps. It gave a 10 point answer, with bullet point sentences arranged alongside headings for each of:
- Current State
- Disruptive Jump
- Impact
Even though the replies to this type of open question do give the sense of being canned answers pulled together from vast training data, it’s available in seconds and it’s a great and inspiring jump start to your own thoughts and insights.
General tips
The trivial example above is all you need to get started productively. There’s no real value in including more detail as everybody’s needs will be so individual, which makes it a matter of experimentation.
Quick tip for those getting started though: most patents in PDF will be an image scan. And most AI interfaces won’t actually absorb the text content (despite assuring you they have!). The easiest path is to use the ‘Scan and OCR’ tool in Adobe Acrobat to make the text available within the PDF, remember to save and use that saved version in your AI interface. (Otherwise, like a skilled fortune teller, the AI assistant will probably cold read any inadvertent context you may have revealed to serve you convincing looking gibberish).
I’ve found my own practices are very highly variable depending on the task at hand, per the many and varied use cases mentioned above.
A first opening stage may concentrate on generally querying:
- overview / summary
- problems solved
- advantages
- inventive concept
- structure / operation of example embodiments
A second stage may be querying for what incremental improvements can be made to a patent. And what disruptive, paradigm-shifting advances would make the patent obsolete as above.
A third stage may dig into asking for a table of component names and their reference numerals. As well as tabulated results of how different components interact. This can be handy to get a quick reference on the terminology used and where it fits in the drawings.
More sophisticated use cases
Returning to the Tesla patent above, you will recall it was published 8 June 2023, and the cover indicates it was filed 27 January 2023. A closer look indicates this patent publication relates to what’s called a continuation application of an earlier patent filed 11 February 2019 and now granted as US 11,567,514 (again, a link to Google Patents).
This earlier patent probably relates to the original Smart Summon feature. And a quick search would indicate if there were other related patents.
Loading the ‘514 patent, and any others that may be available, you could query for the developments made to the patent, and predictions for further refinements in keeping with the original objectives of (say) safety and convenience.
You could also query for differences between the two patent publications, and between the description of the Smart Summon feature outlined in the manual per Fig 2 above. An AI agent is not always the most credible witness of what information it has at its disposal, so the expedient path would be to export the Smart Summon manual page and load it into ChatGPT.
As a personal preference, I find it handy to ask for results in a tabulated form, and this makes it easy to supplement fields of enquiry, or add further patents, or other data sources. And then you can extract that table as an Excel file for later reference.
You can also load the examination file history from USPTO and ask for summaries of the rejection arguments from the examiner and counter-arguments from the attorney. And perhaps what might be better arguments on both sides. Indeed throwing in the most contentious prior art publications can make for a very detailed analysis.
Anyway, in our simple example, the original patent and its possible siblings may have been published before Smart Summon launched, giving you a head start in Tesla’s plans with that feature. This would be valuable intel in the competitive EV market, especially if you wanted to launch a similar or differentiated feature in response.
Automated vs Manual analysis
Consider the highly simplified example analysis above. Yes, you could pull the patent, pull the Smart Summon manual entry, start reading line by line, making notes and forming a report.
Inevitably, all that activity would take a deal longer than the speed of automated analysis. Somebody could easily blow a day or two on a deep dive—and when it takes that line it doesn’t get done unless it’s crucial. Automated analysis makes the exercise feasible, and incremental changes or different lines of enquiry can be seconds away rather that requiring a whole revisit. And when you do invest more substantive time blocks in automated analysis, you can go a lot further a lot quicker.
What is and isn’t in patents
Our random example is great if you have an interest in Smart Summon.
But, say you’re interested in Telsa FSD (Full Self Driving)? After all, that’s of far more strategic interest to other EV manufacturers as the self-driving function is assumed to be a technology of core foundational importance to many use cases.
The situation is more than somewhat surprising. I know from other analysis that despite Tesla having a decently-sized patent portfolio, there are essentially no patents relating to autonomous driving, in terms of the engineering detail. There must be some historical or strategic reason for that. Instead the Tesla patent portfolio leans heavily towards the engineering detail of battery storage and similar.
So there will be gaps, and that is but one. Such a striking omission is not typically the norm with large corporations, but it is certainly typical that patent coverage will be uneven. It is in fact a common response of IP managers—a large proportion of IP manager report that they are under-patented in high priority areas, and over-patented in low priority areas. Priorities change over time, and patents are a longer term investment so this is hardly surprising.
Some cunning IP managers will disguise patents in their portfolio, or sow misdirection in their patents by implying a patent relates to one line of products when it actually relates to another. This type of patent counterintelligence seems to be on the rise, and Apple is the applicant I’ve noticed seems particularly adept at these tactics!
Current Technical limitations of Automated Analysis
This is a big one. While the power and convenience of this analysis can at first feel impressive, there are many caveats. The great news is the possibilities will only improve—drastically and fast.
One bugbear is many AI assistants have memory features within or between sessions which can ruin consistency of results. Sometimes you don’t want extra context, you just want a similar analysis across number of patents. Managing for a clean model is a burden, but you can muddle through well enough. One workaround is loading different patents into a single session, and forcing tabulated answers of a similar desired format.
Also, a big limitation is not unleashing the drawings. Most AI assistants will not easily interpret the drawings of a patent. They’re not set up to see the drawings within a PDF, and the much hyped multimodal features of AI are pretty limited for now.
It may seem like it can talk to drawings in a patent but this is gleaned from the text, in body or sometimes also extracted from the drawings. Drawings in patents are (or should be) largely redundant against the text so this isn’t the biggest issue, but you can rub up against it at times. As an example, creating custom diagrams extracting information from patents in diagrammatic form is not the simplest task but can be done.
This will no longer be a problem soon enough I suspect.
About the blogpost author:
 David is an Australian-based patent attorney operating in digital innovation. Currently, he operates Eureka—a patent boutique in Melbourne, Australia that focuses on early stage technology companies in fintech, artificial intelligence, medical devices and autonomous vehicles amongst other fields. David has predominantly worked in private patent practice with a main focus and expertise relating to computer-implemented inventions, for a range of client types from entrepreneurs to multinationals. After university studies he completed a project in biomedical engineering deciphering ECG ‘noise’ to predict imminent onset cardiac arrhythmia episodes signalled via the degradation of markers for health variability using fractal analysis. David is at present participating as a committee member for The Churchill Club, an organisation that holds regular panel events of themed domain experts discussing major trends affecting particular emerging technologies. David also maintains an interest in IP valuation, and holds post-graduate qualifications in Applied Finance and Investment, as well as Electrical and Computer Systems Engineering and Science degrees from Monash University in Melbourne.
David is an Australian-based patent attorney operating in digital innovation. Currently, he operates Eureka—a patent boutique in Melbourne, Australia that focuses on early stage technology companies in fintech, artificial intelligence, medical devices and autonomous vehicles amongst other fields. David has predominantly worked in private patent practice with a main focus and expertise relating to computer-implemented inventions, for a range of client types from entrepreneurs to multinationals. After university studies he completed a project in biomedical engineering deciphering ECG ‘noise’ to predict imminent onset cardiac arrhythmia episodes signalled via the degradation of markers for health variability using fractal analysis. David is at present participating as a committee member for The Churchill Club, an organisation that holds regular panel events of themed domain experts discussing major trends affecting particular emerging technologies. David also maintains an interest in IP valuation, and holds post-graduate qualifications in Applied Finance and Investment, as well as Electrical and Computer Systems Engineering and Science degrees from Monash University in Melbourne.

